Easysoft ODBC-ODBC Bridge performance white paper
Contents
- General
-
General advice
- ODBC logging
- ODBC-ODBC Bridge authentication
- Connection pooling
- Persistent connections
- Windows: ODBC-ODBC Bridge server threads versus processes
- UNIX: inetd versus standalone server
- Reverse lookups on client IP addresses
- Access control and ODBC-ODBC Bridge server limits
- ODBC data sources
- Client-side threads
- Connection attempts and licensing
- Turning off auditing, access control, and failing SQL logs
- Troubleshooting slow connections
- Simple SQL advice
- Applications and interfaces
- Databases
General
This paper aims to provide all the information that application developers and users need to get the best possible performance from the Easysoft ODBC-ODBC Bridge.
Document conventions
Some sections in this document provide pseudo code. The pseudo code uses constructs that should be familiar to anyone with some programming experience.
Languages differ in their use of string concatenation. Some use '+', some use '.', both or don't need a string concatenation operator. We have used a '+' character to denote string concatenation.
Applications and interfaces
The applications and interfaces specifically addressed in this paper are Microsoft Access, Perl DBI DBD::ODBC, and PHP.
General advice
ODBC logging
ODBC logging is your friend. If you want to find out exactly what ODBC calls are being made from your application or interface, turn ODBC tracing on in the ODBC Driver Manager.
To do this on Windows, in ODBC Data Source Administrator, choose the Tracing tab. Enter a valid trace log filename and choose Start Tracing Now.
To do this on Linux and UNIX with the unixODBC Driver Manager, edit the odbcinst.ini file and add a section like this:
[ODBC] Trace = Yes TraceFile = /tmp/sql.log
Turning on tracing is extremely useful if you did not write the application or interface and don't have the source code. The Driver Manager will log all the ODBC calls and you will get a much better idea of what ODBC calls are being made and the access patterns of the application.
However, bear in mind that turning on tracing in the Driver Manager is the last thing you want to do for high throughput, as tracing is very time consuming and can generate huge log files.
Unfortunately, there are a number of places and ways in which tracing may be turned on and in many cases we come across, some form of tracing is slowing the database connection down. Check the following list to make sure tracing is not turned on in a production environment:
- Check all
odbc.inifiles for lines containingLogging=nwherenis greater than0. Comment them out or set the value to0. - If you are using the unixODBC Driver Manager, check
odbcinst.inifiles and make sure the[ODBC]section does not haveTrace = yes. If it does, setTracetoNoor remove the line entirely. - Make sure you have not turned on tracing on the ODBC-ODBC Bridge server machine. You can check this by going to
http://server_machine:8890. Choose Configuration. Logging should be set to0. Alternatively, on Linux and UNIX, examine the serverodbc.inioresoobserver.inifile or, on Windows, examine the registry for:HKEY_LOCAL_MACHINE\ SOFTWARE\ Easysoft ODBC-ODBC Bridge\ Configuration\ System\ Settings\ Logging
-
On Windows, make sure Driver Manager tracing is not turned on. You can check this by going in to the ODBC Data Source Administrator and clicking on the Tracing tab.
- Check your application is not turning ODBC tracing on by calling
SQLSetConnectAttr(SQL_ATTR_TRACE, SQL_OPT_TRACE_ON).
ODBC-ODBC Bridge authentication
By default, the ODBC-ODBC Bridge server authenticates each user connecting to it.
The ODBC-ODBC Bridge client passes an operating system user name and password to the server, which the server then passes to the operating system to validate. On both Windows and UNIX, the ODBC-ODBC Bridge server then becomes that user for the duration of the client connection.
On Windows in particular, this can be quite a lengthy process depending on where your Primary Domain Controller (PDC) is located and what it is doing. If you're happy accessing the ODBC-ODBC Bridge server without operating system authentication, turning off ODBC-ODBC Bridge server authentication can make a big difference to connection times.
Here are some sample times from Linux to Windows where the Windows machine is the PDC and is running Microsoft SQL Server (which we use as the database). The results are the average of 50 consecutive connections.
time in seconds with authentication enabled (default) : 0.486s time in seconds with authentication disabled : 0.174s
If your PDC is busy or it takes longer to contact it, the difference between authenticated or not might be much larger.
Neither of these times are likely to bother a normal user logging in to a workstation on your network but if say the ODBC-ODBC Bridge is running under your web server to connect to your remote database thousands of times a day, this may prove a significant difference.
To turn off ODBC-ODBC Bridge server authentication, change the configuration in the ODBC-ODBC Bridge server Web Administrator.
Connection pooling
Connection pooling is where the Driver Manager keeps hold of open connections when SQLDisconnect is called so they may be used again. The Driver Manager stores the connection string used to SQLDriverConnect (or SQLConnect) with each connection it opens so it may be reused if SQLDriverConnect or SQLConnect is called with the same connection string. Usually, there's a timeout associated with a pooled connection such that if the pooled connection is not used again within the timeout period, the Driver Manager will drop it.
Connection pooling can significantly speed up applications that repeatedly open and close ODBC connections.
With the ODBC-ODBC Bridge, there are two sides of the operation to consider, the client end and the server end. Both connect to an ODBC Driver Manager. Connection pooling at the ODBC-ODBC Bridge server end will speed up access to the final ODBC driver for your database. Connection pooling at the ODBC-ODBC Bridge client end will speed up access to the ODBC-ODBC Bridge server.
To turn on connection pooling on Windows, use ODBC Data Source Administrator. Select the Connection Pooling tab, double-click the driver you're using, choose Pool Connections to this driver and enter a timeout in the field labelled Time that unused connections remain in the pool in seconds.
For the unixODBC Driver Manager, edit the odbcinst.ini file, add Pooling = Yes to the [ODBC] section and then add a CPTimeout value to the driver section. For example:
[ODBC] Trace = No Trace File = /tmp/sql.log Pooling = Yes [ODBC-ODBC Bridge] Description = Easysoft ODBC-ODBC Bridge Driver = /usr/local/easysoft/oob/client/libesoobclient.so Setup = /usr/local/easysoft/oob/client/libesoobsetup.so FileUsage = 1 CPTimeout = 120
As an example of the difference connection pooling can make, we run the same test shown earlier but with connection pooling turned on. The average time per connection after 50 consecutive connections was 0.007 seconds.
There are a few additional considerations you should note:
- Pooled connections that have timed out are only closed when another connection to the same Driver Manager is made.
- Pooled connections are generally only process wide.
This is a very important point especially with respect to the ODBC-ODBC Bridge server, which normally runs in a multi-threaded mode, but can run in a multi-process mode. If the ODBC-ODBC Bridge server is running in multi-process mode then connection pooling at the server is not viable as the ODBC-ODBC Bridge server starts a new process for each incoming connection.
In addition, a popular initial candidate for using pooled connections at the client end is a web server like Apache. Here again, you need to remember that most web servers fork child processes to handle the connections. The pooled connections are only within the individual web server processes and are not web server wide, unless the web server is multi-threaded.
- Pooling connections may cause you to have more open database connections at any one time than you did prior to pooling connections. (This may have licensing implications within your database.)
For example, suppose you turn on connection pooling for driver X and run applications from one or more clients that make connections to multiple data sources all in the same database. If the connection pooling timeout is set to 120 seconds but 120 seconds elapses before that connection is reused, you effectively had a connection open for an additional 120 seconds (compared with non-pooled scenario). If you have limited licenses for your database (or for ODBC-ODBC Bridge) then this could cause you to hit the license limit. The worst scenario would involve many clients that connect infrequently, as each of their connections would be held open for at least 120 seconds after they disconnected and possibly a lot longer if no other connections were made through the same Driver Manager.
A classic case of this is a web server. Most web servers create multiple processes to handle HTTP requests. If you turn on connection pooling then you will potentially have n open database connections (where n is the number of HTTP server processes). Since you generally have little control over how the main web server process hands off pages to its child processes, with sufficient traffic, you eventually end up with a lot of pooled connections.
For example, assume you configure your web server to only allow it to start 5 child processes to handle connections. Assume you have turned on connection pooling, have a timeout of 120 seconds, and you have one page on your web site that requires ODBC access. Assume the page that requires ODBC access is hit once every 20 seconds. If the web server hands out the HTTP request for the ODBC-enabled page to a different child each of the first 5 times the page is hit then you have 5 concurrent connections to the database after 100 seconds. Without connection pooling, you would only have had 1 concurrent connection at any one time.
Refer to the ODBC-ODBC Bridge knowledge base article Why do my ODBC-ODBC Bridge connections drop?
Persistent connections
Persistent connections are really just the same mechanism as connection pooling except that, in general, the application or interface does the pooling instead of the ODBC Driver Manager.
Where possible, we would recommend using ODBC Driver Manager connection pooling over any application-specific persistent connection method.
Refer to the connection pooling section, as most of the notes there are applicable to persistent connections.
Refer also to the ODBC-ODBC Bridge knowledge base article Why do my ODBC-ODBC Bridge connections drop?
Windows: ODBC-ODBC Bridge server threads versus processes
The ODBC-ODBC Bridge server for Windows may be configured to run in multi-process mode or multi-threaded mode. In multi-threaded mode (the default), the ODBC-ODBC Bridge server starts a new thread to handle each incoming client connection. In multi-process mode, the ODBC-ODBC Bridge server starts a new process for each incoming connection.
Multi-process mode in the ODBC-ODBC Bridge server was originally written to allow connection to thread-unsafe ODBC drivers. (For example, JET implementations before JET 4.0.)
There are a few differences between running the server in multi-threaded or multi-process mode, which can impact throughput and resources:
- Windows tends to create threads quicker than processes. As a result, connection times for a multi-threaded ODBC-ODBC Bridge server are slightly less.
For our connection test mentioned above, the multi-threaded server handled 150 consecutive connections from the same application in 20.3 seconds compared with 22.7 seconds in the multi-process server.
- Windows seems to allocate CPU in a fairer way between processes than threads in a process. As a result, the multi-process ODBC-ODBC Bridge server tends to be quicker after connection when there are multiple concurrent connections.
- The multi-threaded ODBC-ODBC Bridge server uses less resources (machine wide handles and memory).
UNIX: inetd versus standalone server
The ODBC-ODBC Bridge server for UNIX is installed by default under {x}inetd. This means inetd listens on a port on behalf of the ODBC-ODBC Bridge server and when a connection is made to that port it runs a shell script that starts an ODBC-ODBC Bridge server process, which inherits the socket connection. Some sites also use tcp wrappers in their inetd configuration file to provide access control to the ODBC-ODBC Bridge server.
The ODBC-ODBC Bridge server may be run in standalone mode without inetd. In this mode, the ODBC-ODBC Bridge server listens on the port and forks a child process to handle each connection.
Running the ODBC-ODBC Bridge server in standalone mode is quite a bit quicker because there is a lot less to do (one less fork, server configuration file read on startup instead of once per connection, and so on). It also has the advantage that you can run the ODBC-ODBC Bridge HTTP administration server to find out what is going on in the ODBC-ODBC Bridge server.
Refer to the ODBC-ODBC Bridge manual or the knowledge base article Can I run the ODBC-ODBC Bridge server on UNIX without the inetd Super-Server?
The inetd server only has one advantage: if the main standalone ODBC-ODBC Bridge server terminates no connections are possible until it is restarted. This is not true of an inetd started server.
If you are using {x}inetd and making a lot of connections in short periods of time, refer to the ODBC-ODBC Bridge knowledge base article Why is inetd terminating the ODBC-ODBC Bridge server service?.
Reverse lookups on client IP addresses
When a client connects to the ODBC-ODBC Bridge server, it can do a reverse lookup on the client's IP address. The resulting string may be used in the ODBC-ODBC Bridge's audit trail file and various notices the ODBC-ODBC Bridge server issues.
To do this successfully, you need a working DNS server or a hosts lookup table with the client's IP address. If your DNS server is not contactable most DNS clients will make multiple attempts and this will slow connections down a lot.
For fastest possible connections turn off the ODBC-ODBC Bridge server's ReverseLookup in its configuration page. (Refer to the ODBC-ODBC Bridge server configuration chapter of the manual for how to do this.)
Refer to Does the ODBC-ODBC Bridge rely on DNS? in the ODBC-ODBC Bridge knowledge base for further relevant information.
Access control and ODBC-ODBC Bridge server limits
The ODBC-ODBC Bridge server contains access control rules that define which clients can access the server. Server access control rules also control access to specific data sources.
These access control lists are a vital part of the security built in to ODBC-ODBC Bridge, but they can also consume time during initial connection. For this reason, you should try and keep your access control rules short and concise.
There are two connection-based limits in the ODBC-ODBC Bridge server: MaxThreadCount and MaxClientConnect. MaxThreadCount limits the total number of threads or processes the ODBC-ODBC Bridge server creates to handle client connections. MaxClientConnect limits the total number of concurrent connections from a particular client.
Both of these limits are useful in throttling the ODBC-ODBC Bridge server but they have one drawback. At any one time, the ODBC-ODBC Bridge server does not know accurately how many active connections there are (refer to the ODBC-ODBC Bridge manual for a description of why). As a result, when you set either of these limits, the ODBC-ODBC Bridge server has to cycle through the created threads or processes and find out if any have terminated. If you have many concurrent connections, this can lengthen the connection time quite considerably.
ODBC data sources
A data source name is a logical name for a data repository or database. Any attributes that define a data source are stored under the DSN for retrieval by the driver.
In the case of the ODBC-ODBC Bridge, the data source name is the key to a set of attributes in odbc.ini (LInux or UNIX) or the registry (Windows).
When the application calls SQLDriverConnect or SQLConnect with a DSN, the Driver Manager uses the DSN to locate the relevant driver, loads the driver and calls SQLDriverConnect or SQLConnect in the driver with the same connection strings.
The ODBC-ODBC Bridge client can look up other attributes it needs for the connection in odbc.ini or the registry.
When the ODBC-ODBC Bridge server calls SQLDriverConnect or SQLConnect it is acting like an ordinary ODBC application.
You should consider exactly what happens in the Driver Manager when you call SQLDriverConnect or SQLConnect with a data source name. On Windows, the Driver Manager needs to locate the data source name in the registry, pull out the name of the driver, load the driver, and then pass the ODBC calls on to the driver. The same is true for Linx and UNIX except that the registry is replaced with the odbcinst.ini and odbc.ini files. Parsing these files when there are a large number of DSNs can make a large difference to connection times.
This is a slightly exaggerated example, but here are some timings for an odbc.ini file containing one DSN and an odbc.ini file containing 60 DSNs with the DSN we want last in the file:
timings for 50 connects/disconnects one DSN inodbc.inifile : 28s 60 DSNs inodbc.inifile and required DSN last in file : 42s
Note In later unixODBC versions, the difference is significantly less if all the connects and disconnects are done in the same process because the unixODBC Driver Manager caches values parsed from the ini files.
There is another aspect with respect to connection attributes. If your application calls SQLDriverConnect or SQLConnect with a DSN name and nothing else then the ODBC-ODBC Bridge client needs to examine the registry or odbc.ini to obtain the other attributes it needs to complete the connection to the server. (For example, Server, TargetDSN, and so on.) Any connection attribute that may be specified in the registry or odbc.ini may be specified in the connection string. For optimum speed, you may want to pass all the required connection attributes in the connection string.
On UNIX and Linux, there is one last possibility for slowing down the connection, which is related to how the ODBC-ODBC Bridge client and the unixODBC ODBC Driver Manager locate DSNs. The ODBC-ODBC Bridge client looks for DSNs in the following places (in order):
ODBCINI (environment variable) <cwd>odbc.ini<cwd>.odbc.ini(UNIX only, not VMS) <home>odbc.ini<home>.odbc.ini(UNIX only, not VMS) /etc/odbc.ini(SYS$ROOT:odbc.inifor VMS) - system DSNs only <wherever unixODBC stores DSNs>
Obviously, it takes time to examine the file system for all these files, read them, and look for the DSN. The sooner your DSN is found the quicker the initial connect will be. In particular, if you have built the unixODBC Driver Manager yourself, the configure script defaults sysconfdir (where unixODBC looks for system DSNs) to /usr/local/etc/odbc.ini. The ODBC-ODBC Bridge client does not look in /usr/local/etc/odbc.ini itself, partly because unixODBC can be configured to use any directory. Instead, if the ODBC-ODBC Bridge client has not found your DSN, it attempts to dynamically load unixODBC's libodbcinst shared object and then use the SQLGetPrivateProfileString API to retrieve DSN attributes. This process takes a lot longer than if ODBC-ODBC Bridge finds the DSN itself. One way to speed this up is to locate the odbc.ini unixODBC uses for system DSNs and then symbolically link /etc/odbc/ini to that file. In this way ODBC-ODBC Bridge locates the DSN a lot quicker and unixODBC continues to work.
Client-side threads
One way you might think would automatically increase the throughput from your application is to make it multi-threaded. This can be true. But there are a few things to think about first:
- Can you divide your database access up in a meaningful way to distribute the work between threads?
- Are you using a thread-safe ODBC-ODBC Bridge client? The Windows ODBC-ODBC Bridge client is thread-safe, but for Linux and UNIX, there are separate distributions for thread-safe and thread-unsafe drivers. The Linux and UNIX distributions containing the thread-safe ODBC-ODBC Bridge client and unixODBC Driver Manager have
-mtin the distribution name and contain ODBC-ODBC Bridge client shared objects with_rin the name. - Making multiple threads use the same connection is not going to produce any performance increase. The reason for this is that the ODBC-ODBC Bridge client's network library serialises access to the socket connected to the server (there is one socket per ODBC connection). To get the maximum benefit from multiple threads using ODBC, each thread should run with its own ODBC connection handle.
Connection attempts and licensing
There are a few remaining configurable parameters for the ODBC-ODBC Bridge client and server that can affect connection times.
ConnectAttempts
For the ODBC-ODBC Bridge client, ConnectAttempts specifies how many attempts the client makes to connect to a server.
The ODBC-ODBC Bridge client makes ConnectAttempts = n connection attempts if the server operating system returns ECONREFUSED (connection refused). The reason for this is that on some platforms, the listen backlog can only be set to a low level, so if there is a sudden rush of connections, the operating system may turn some down before the ODBC-ODBC Bridge server gets them. When ECONREFUSED is received by the client, it waits connection_attempt * 0.1 seconds before trying again up to a maximum of ConnectAttempts times.
Here's an example where ConnectAttempts is 5 (the default) and the server always refuses the connection:
connect attempt 1 - refused by server wait 0.1 seconds connect attempt 2 - refused by server wait 0.1*2 seconds . . . connect attempt 5 - refused by server client gets error diagnostic: 08001:1:4:[Easysoft ODBC (Client)] Client unable to establish connection HY000:2:4:[Easysoft ODBC (Client)] Connection refused, connect(), after 5 attempts
and here is an example where the first few attempts are refused due to the listen backlog queue being full, but by the third attempt, the backlog is cleared and the connection accepted:
connect attempt 1 - refused by server wait 0.1 seconds connect attempt 2 - refused by server wait 0.1 * 2 seconds connect attempt 3 connection accepted by server operating system
ConnectAttempt is 5 by default, but it may be modified in the ODBC-ODBC Bridge client DSN. For example:
[mydsn] Driver = ODBC-ODBC Bridge . . ConnectAttempts = 3
The ConnectAttempt value takes on extra importance if you have specified multiple servers and ports in a client DSN entry. In this scenario, you specifically want an ODBC-ODBC Bridge client that can't contact to the first ODBC-ODBC Bridge server to fallover to the second and subsequent servers as quickly as possible. In this situation, you want ConnectAttempt to be as low as possible. For example, 1.
RetryCount and RetryPause
The RetryCount and RetryPause configurable parameters affect what the ODBC-ODBC Bridge server does under two situations:
- Resource use on your server is such that the ODBC-ODBC Bridge server is unable to create a new thread or process to handle the current incoming connection.
- You have used all your available license slots.
In each of these cases, the RetryCount value specifies the number of additional attempts the server makes to obtain this resource and the RetryPause is the time in seconds it waits between attempts.
The default value for RetryCount is 5. The default value for RetryPause is 3.
You can modify these values in the ODBC-ODBC Bridge Web Administrator.
The default values are set in an attempt to let you maximise the use of your license slots. If you have many clients connecting and disconnecting then there may be times when all your license slots are in use for short periods of times. Rather than just return to the client, the server is assuming (with the default values) that a license slot will become available soon. However, the net effect of the default values when no license slots become available is to delay informing the client that there are no license slots available for 15 seconds.
Only you can determine what your desired behaviour here should be.
Turning off auditing, access control, and failing SQL log
The ODBC-ODBC Bridge server contains functionality to:
- Log all failing SQL (the LogFailingSQL setting in the ODBC-ODBC Bridge Web Administrator). This is a valuable debugging aid, but costs resources (in the storing of the SQL until a time when it is known whether the SQL has succeeded or failed) and if the SQL fails, costs time to write the failing SQL to the log.
- Audit all connections, connection failures, OS authentication failures, and so on. Each auditable event is a write to the audit trail file. Avoiding auditing speed up the ODBC-ODBC Bridge server. (This is the AuditODBCAccess setting in the ODBC-ODBC Bridge Web Administrator.)
- Do access control. There are two types of access control:
- Access control rules defining which client machines can connect to the ODBC-ODBC Bridge server. Processing this access control list adds a small amount of processing time to the main ODBC-ODBC Bridge server.
- DSN access control defining which client machines and users can connect to a particular DSN. Handling this form of access control requires slightly more processing than the first type, since the ODBC connection string has to be parsed to ascertain the DSN.
Using any or all of these options has a small effect on ODBC-ODBC Bridge server resources and processing. If you are looking for the optimum performance and are prepared to lose these features, turn them off in the ODBC-ODBC Bridge Web Administrator.
Troubleshooting slow connections
If you believe connections to the ODBC-ODBC Bridge server from the client are taking too long then there are a number of things you can do to check this out. However, first you need to determine if the connection time to expect is realistic. As a rough guide, we have found that it takes less than a tenth of a second to connect an application linked directly with the ODBC-ODBC Bridge client on Linux to a data source on Windows over a 100 Mbit/s Ethernet link, where both machines are on the same LAN and are mostly idle and ODBC-ODBC Bridge server authentication is turned off. This is a small fraction of a second slower for interpreted languages like Perl or if there is a Driver Manager (like unixODBC) between the application and the ODBC-ODBC Bridge client. It can be considerably slower on Windows if ODBC-ODBC Bridge server authentication is turned on as a lot depends on what your PDC is doing and where it is located on your network.
If you're still convinced something might not be configured correctly, check the following:
-
Are the client and server machines on the same Local Area Network (LAN)? Connection times can increase dramatically if they are not. Try pinging the server from the client to find out what return times you get.
For example:
ping www.easysoft.com PING www.easysoft.com (194.131.236.4): 56 data bytes 64 bytes from 194.131.236.4: icmp_seq=0 ttl=255 time=0.6 ms 64 bytes from 194.131.236.4: icmp_seq=1 ttl=255 time=0.1 ms
In this case, the return time is less than 0.6 ms (quick). Machines not on the same LAN can show a much greater time and this will be reflected in your ODBC connection times.
For example:
ping www.whitehouse.gov PING www.whitehouse.gov (193.50.203.51) : 56 data bytes. 64 bytes from 193.50.203.51: icmp_seq=0 ttl=240 time=34.5 ms 64 bytes from 193.50.203.51: icmp_seq=1 ttl=240 time=35.2 ms
This is relatively slow.
- Check that ODBC tracing is not turned on.
- If the ReverseLookup configurable parameter in the ODBC-ODBC Bridge server is turned on, turn it off, and try again.
- Check you are not running out of license slots temporarily.
- Check the size of your
odbc.inifiles or the registry and the position of the DSN you are using within it. Refer to the ODBC data sources. - If you're using Microsoft SQL Server, refer to the advice under Microsoft SQL Server.
- If you're using Windows 2000, refer to the ODBC-ODBC Bridge knowledge base and the article Why have connection times to Microsoft SQL Server slowed down since upgrading to SQL Server 2000?.
- Work through the examples of using
oobpingin Usingoobpingto help diagnose slow connections.
Using oobping to help diagnose slow connections
oobping is a small program distributed with the ODBC-ODBC Bridge since version 1.0.0.35. oobping is a valuable tool for checking ODBC-ODBC Bridge connectivity and diagnosing connection problems or connection timing issues.
A full description of oobping may be found in the ODBC-ODBC Bridge manual and these ODBC-ODBC Bridge knowledge base articles:
-
What is
oobping? -
How do I use
oobpingto diagnose connection problems to the ODBC-ODBC Bridge server? -
How do I use
oobpingto diagnose authentication problems? -
How do I use
oobpingto test the connection to a remote ODBC data source? -
How do I use
oobpingto test connection times?
On Windows, you'll find oobping.exe in installdir\Easysoft\Easysoft ODBC-ODBC Bridge.
On Linux and UNIX, there are two versions of oobping. oobpings (a statically linked version) and oobpingd (a dynamically linked version linked against the libesoobclient shared object). These programs are located in installdir/easysoft/bin. To use oobpingd, you may need to set and export LD_LIBRARY_PATH, LD_RUN_PATH, or LIBPATH to include installdir/easysoft/oob/client and installdir/easysoft/lib.
oobping has the following command line:
oobping [-h host | -d ODBC_connection_string] {-t port}
{-u osuser} {-p ospassword} {-e}
where:
host |
The name or IP address of the machine on which the ODBC-ODBC Bridge server is running. |
ODBC_connection_string |
The ODBC connection string. This is a list of semi-colon separated attribute=value pairs. For example, DSN=test;UID=fred;PWD=bloggs;.
If you specify |
port |
The port on which the ODBC-ODBC Bridge server is listening. |
osuser |
A valid user name on the host operating system. |
ospassword |
A password for the user specified with -u. |
In ODBC-ODBC Bridge 1.1.0.0 and later, oobping has the -e option, which times the requested operation. This can be invaluable in diagnosing a slow connection and determining which phase the problem is occurring in.
If you don't have a version that supports the -e switch, use the UNIX time function in front of the oobping command instead.
A simple example is:
==========
oobping -e -h myserver -t 8888
Host: myserver, Port: 8888
Attempting connection...OK
Examining Server...
ODBC-ODBC Bridge server Version: 1.1.0.00
ODBC-ODBC Bridge server Name: ODBC-ODBC Bridge
Time for execution: 0.16s
==========
If this is repeated with -u and -p, you can work out the extra time required to perform the operating system log on:
==========
oobping -e -h myserver -u myosuser -p mypassword
Host: myserver, Port: 8888
Attempting connection...OK
Examining Server...
ODBC-ODBC Bridge server Version: 1.1.0.00
ODBC-ODBC Bridge server Name: ODBC-ODBC Bridge
Trying to authenticate...OK
Time for execution: 0.52s
==========
This example clearly demonstrates the extra time required to authenticate a user.
The next example shows a full connection to the ODBC-ODBC Bridge server. The example command uses ODBC-ODBC Bridge server authentication and makes a remote ODBC connection:
========== oobping -e -d "DSN=test;" Using Connection string : DSN=test; Connected OK 01000:1:5701:[NetConn: 0172c620][Microsoft][ODBC SQL Server Driver] [SQL Server]Changed database context to 'test'. 01000:2:5703:[NetConn: 0172c620][Microsoft][ODBC SQL Server Driver] [SQL Server]Changed language setting to us_english. OutConnectionString: DSN=test;SERVER=myserver;TRANSPORT=tcpip;PORT=8888;TARGETDSN=test; UID=dbuser;PWD=dbauth;LOGONUSER=me;LOGONAUTH=mypassword; Connected to database: test DBMS Name: Microsoft SQL Server Driver Name: esoobclient Driver Version: 01.00.0043 Disconnecting Time for execution: 0.78s ==========
The output demonstrates the extra time required to connect to the remote ODBC data source.
Simple SQL advice
- Only select the columns you need in your SQL queries. Generating result sets containing columns you don't need just wastes time in the ODBC driver. Worse still, some ODBC drivers have no choice but to read the column data from the database even though you never access it. Doing this also helps protect your application from table changes (for example, the addition of a new column).
- Try batching your SQL. For example:
SELECT * FROM table1; SELECT * FROM table2You can use
SQLMoreResultsto get the second result set. - If your database supports stored procedures, you can often realise performance gains by coding your SQL statements into them. In most cases:
- The SQL statements are parsed and compiled once when the procedure is created and not when the procedure is used by your application.
- Often a call to a stored procedure requires sending less data over the network between the ODBC driver and the database than the equivalent SQL.
Applications and interfaces
Using ODBC directly
In ODBC, there are multiple ways of retrieving query result sets and inserting data. Picking the right one for your application is crucial in determining throughput. Here, we examine the simplest ways of retrieving result sets and inserting data and then gradually improve the methods to get more speed. The code examples are pseudo code.
To provide meaningful results we have used a table containing 5 columns: an INTEGER, a CHAR(30), a VARCHAR(255), a TIMESTAMP, and a FLOAT. The table is created with 50000 rows.
Retrieving result sets
The simplest mechanism for issuing a query and retrieving a result set is:
SQLExecDirect("query producing a result set") columns = SQLNumResultCols() while (SQLFetch() succeeds)
{
for (col = 1; col < = columns; col++)
{
column_data = SQLGetData(col, SQL_C_CHAR)
}
}Here, all the columns are retrieved as SQL_C_CHARs so the database has to convert the INTEGER column and the TIMESTAMP column to a string.
The C code for the above algorithm took 47 seconds to run.
One possible change that might speed the code up is to fetch the columns as their native types. For example, the INTEGER as a SQL_C_LONG, the TIMESTAMP as a SQL_C_TIMESTAMP, and the FLOAT as a SQL_C_FLOAT. This avoids the ODBC driver converting the native type to a SQL_C_CHAR string. The pseudo code for this looks like:
SQLINTEGER idata
SQLFLOAT fdata
SQL_TIMESTAMP_STRUCT ts
SQLCHAR cdata1[256]
SQLCHAR cdata2[256]
idata = SQLGetData(1, SQL_C_LONG);
cdata = SQLGetData(2, SQL_C_CHAR);
cdata2 = SQLGetData(3, SQL_C_CHAR);
ts = SQLGetData(4, SQL_C_TIMESTAMP);
fdata = SQLGetData(5, SQL_C_FLOAT);However, when we run this version of the program, we discover that it takes 62 seconds to run (longer). The main reasons for this are:
- The float's representation on the server platform is not necessarily the same as the client platform, so ODBC-ODBC Bridge has to convert them from the server's representation to the client's representation.
- The timestamp is a structure that the ODBC-ODBC Bridge splits up to transfer over the network and then has to put the timestamp back together at the client end.
Doubles are the same as floats in this respect and SQL_DATEs, SQL_TIMEs, and SQL_NUMERICs are the same as timestamps.
One way we might be able to speed things up is to use ODBC bound columns. With bound columns, you bind memory addresses to each column and when SQLFetch is called the entire row is returned in one go without having to call SQLGetData individually for each column. The pseudo code for this is:
SQLINTEGER idata
SQLFLOAT fdata
SQL_TIMESTAMP_STRUCT ts
SQLCHAR cdata1[256]
SQLCHAR cdata2[256]
SQLBindCol(1, &idata)
SQLBindCol(2, cdata1)
SQLBindCol(3, cdata2)
SQLBindCol(4, &ts)
SQLBindCol(5, &fdata)
SQLExecDirect"query"producing"a"result"set"while (SQLFetch() succeeds)
{
; SQLFetch has placed the column data into our variables
}The time for this implementation is 22 seconds, half of what we started with. The main reason for this being a lot faster is that the ODBC-ODBC Bridge server can send an entire row back to the client in one network call. A good rule of thumb for the ODBC-ODBC Bridge is: reducing the number of remote ODBC calls speeds the application up.
The last example used column-wise binding but we only retrieved one row at a time. ODBC has a facility for returning more than one row of column-bound columns at a time. To turn on this facility, you call SQLSetStmtAttr with an argument of SQL_ATTR_ROW_ARRAY_SIZE and pass in the number of rows you want in one go.
The pseudo code looks like this:
define ROWS 10
SQLINTEGER idata[ROWS]
SQLFLOAT fdata[ROWS]
SQL_TIMESTAMP_STRUCT ts[ROWS]
SQLCHAR cdata1[ROWS][256]
SQLCHAR cdata2[ROWS][256]
SQLSetStmtAttr(SQL_ATTR_ROW_ARRAY_SIZE, ROWS)
SQLBindCol(1, &idata)
SQLBindCol(2, cdata1)
SQLBindCol(3, cdata2)
SQLBindCol(4, &ts)
SQLBindCol(5, &fdata)
SQLExecDirect("query producing a result set")
while (SQLFetch() succeeds)
{
; SQLFetch has placed the column data into our variables
}When we run this implementation, the time to retrieve the 50000 rows goes down to 5 seconds, one ninth the time of our first implementation.
The speed increase of using bound columns is usually greater the more columns there are in the result set. In addition, setting SQL_ATTR_ROW_ARRAY_SIZE greater than 1 tends to provide larger amounts of consecutive bytes for column data, which the ODBC-ODBC Bridge will favour for data compression when transferring the data over the network.
There is one other option, which is row-wise binding of columns. In row-size binding, you create a structure with one field for each column, ask for row-wise binding, and then pass the address of each field in the structure to SQLBindCol and the size of the structure. It is basically the same as column-wise binding except that you set SQL_ATTR_ROW_ARRAY_SIZE to a value greater than 1. With column-wise binding, each address passed to SQLBindCol is supposed to be the base address of an array of that column type. With row-wise binding, you create an array of your row structures.
For the ODBC-ODBC Bridge, row-wise binding is a little slower. The ODBC-ODBC Bridge client does not actually pass the call to set SQL_BIND_TYPE through to the driver when the type is anything other than xxx_BIND_BY_COLUMN. The ODBC-ODBC Bridge leaves the bind type set to column-wise binding, notes the application wants row-wise binding and converts the returned data to row-wise. This makes no difference to any application that uses row-wise binding as it works as ODBC dictates, but it's one of the few instances in the ODBC-ODBC Bridge where what the application asks for (in ODBC terms) is not mirrored at the server side.
Inserting data
These examples use the same table structure as in the previous section, but this time we want to populate the table with 50000 rows.
The simplest pseudo code to populate our table is:
SQLCHAR sql[1024]
for (i = 1; i <= 50000; i++)
{
sql = "INSERT INTO perf VALUES " +
"(" + i + ", 'this is a char thirty', " +
"'this is a varchar 255', " +
"{ts '2002-08-01 11:12:13.123'}, " + i * 1.1 + ")"
SQLExecDirect(sql);
}Here, we construct the SQL INSERT statement once for each row and call SQLExecDirect once for each row. When we run this code, it takes 5 minutes and 10 seconds. Why? The first problem with this code is the database has to parse and prepare the INSERT statement once per row; this can be time consuming.
A much more efficient method is to use a parameterised insert. Here, parameters are using in place of the column data. Instead of the above SQL, we would use:
INSERT INTO PERF VALUES (?,?,?,?,?)We prepare this SQL once (by calling SQLPrepare, bind the parameters with SQLBindParameter, and then just keep calling SQLExecute, changing the data we bound each time. For example:
SQLINTEGER idata
SQLCHAR cdata1[256]
SQLCHAR cdata2[256]
SQL_TIMESTAMP_STRUCT ts
SQLREAL fdata
SQLPrepare(INSERT INTO perf VALUES (?,?,?,?,?)
SQLBindParameter(1, idata)
SQLBindParameter(2, cdata1)
SQLBindParameter(3, cdata2)
SQLBindParameter(4, ts)
SQLBindParameter(5, fdata)
for (i = 0; i <= 50000; i++)
{
set idata, cdata1, cdata2, ts, fdata to whatever values you
want to insert
SQLExecute()
}However, if you run this through the ODBC-ODBC Bridge, you'll find that it does not make any real difference. The reason for this is that in the first case with the straightforward SQL INSERT, you're making one network call per INSERT whereas with the parameterised INSERTs, there are two network calls; one for SQLExecute and one to send the parameters. (The ODBC-ODBC Bridge also has some extra work to pack up the parameters.)
With many databases, a very easy speed up if you are doing bulk inserts, copying large quantities of data from one place to another, is to turn autocommit off and commit the inserts at the end. This can half the insert time. For example:
SQLSetConnectAttr(SQL_ATTR_AUTOCOMMIT, SQL_AUTOCOMMIT_OFF)
<pseduo code above>
SQLEndTran(SQL_HANDLE_DBC, connection_handle, SQL_COMMIT)When we apply this change and run to Microsoft SQL Server, DB2, or Oracle, the time comes down to around 2 minutes 30 seconds; this is nearly half of what we started with. There are two things to remember about this:
- If you only commit at the end of all your inserts then if you abort when any
SQLExecutefails, none of your inserts are committed. - Individual inserts will not be visible to other users until you have finished all your inserts and committed them. If this bothers you then perhaps you can still get improved speed by committing less often.
One final change we can make is to use arrays of parameters (as we did in row fetching). To do this, you call SQLSetStmtAttr and set the SQL_ATTR_PARAMSET_SIZE to a number greater than 1. For example:
#define ROWS 10
SQLINTEGER idata[ROWS]
SQLCHAR cdata1[ROWS][256]
SQLCHAR cdata2{ROWS][256]
SQL_TIMESTAMP_STRUCT ts[ROWS]
SQLREAL fdata[ROWS]
SQLSetStmtAttr(SQL_ATTR_PARAMSET_SIZE, ROWS)
SQLPrepare(INSERT INTO perf VALUES (?,?,?,?,?)
SQLBindParameter(1, idata)
SQLBindParameter(2, cdata1)
SQLBindParameter(3, cdata2)
SQLBindParameter(4, ts)
SQLBindParameter(5, fdata)
for (i = 0; i <= 5000; i++)
{
set idata, cdata1, cdata2, ts, fdata to whatever values you
want to insert (* 10)
SQLExecute()
}Note this code only does 5000 iterations as you are inserting 10 rows at a time. The time for this version was 34 seconds. If you take this further, inserting 50 rows at a time, it falls again to 18 seconds, but there is usually a limit at which the speed increase bottoms out. This final figure works out as 2777 inserts a second.
Cursors
Overview
In ODBC, a cursor is automatically opened for each result set and an application retrieves rows through the cursor using SQLFetch, SQLFetchScroll, or SQLExtendedFetch. An application can change the cursor using SQLSetStmtAttr before executing a SQL statement, but it should be noted that the ODBC driver may change these settings as it sees fit. If this is the case, the ODBC driver returns an "option value changed" diagnostic.
The default settings for cursor options are:
SQL_ATTR_CURSOR_TYPE - SQL_CURSOR_FORWARD_ONLY
SQL_ATTR_CONCURRENCY - SQL_CONCUR_READ_ONLY
SQL_ROWSET_SIZE/SQL_ATTR_ROW_ARRAY_SIZE - 1An application can change the SQL_ATTR_CURSOR_TYPE to one of the following types:
- Static cursors (
SQL_CURSOR_STATIC).In a static cursor. the result set is unchanging once a particular row has been fetched (for some ODBC drivers, the result set is built when the cursor is opened). The cursor does not reflect any changes made in the database with respect to fetched rows in the result set or values in the columns. A static cursor always returns the result set as it was at the time the cursor was opened or a row was fetched. Any rows added or deleted or column data changed since the cursor was created that satisfy the conditions of the query are not seen until the cursor is reopened. Static cursors are read-only.
- Dynamic cursors (
SQL_CURSOR_DYNAMIC).Dynamic cursors are the opposite of static cursors; they reflect all changes made to the rows in the result set as the user scrolls around the cursor. The data values and rows in the cursor can change dynamically on each fetch.
The cursor shows all deleted, inserted, and updated records, whether they were made by the application with the dynamic cursor or by something else.
You cannot use fetch absolute to position the cursor somewhere in the result set, as the size of the result set and the position of the rows within the result set are not constant.
- Forward-only cursors (
SQL_CURSOR_FORWARD_ONLY).This is the same as a dynamic cursor except that you can only fetch the rows in the result set in sequence from the start to the end of the cursor.
- Keyset-driven (
SQL_CURSOR_KEYSET_DRIVEN).With keyset-driven cursors, the rows in the result set and their order is fixed when the cursor is opened. Keyset-driven cursors are controlled using a set of unique identifiers (keys) known as the keyset. The keys are built from the set of columns that uniquely identify the rows. The keyset is the set of all the key values that made up the rows in the result set when the cursor was opened.
Changes to the values of columns that are not in the keyset (made by the current application or something else) are reflected in the rows as the cursor is scrolled through. Inserts are not reflected (the cursor needs to be closed and reopened to reflect inserts). Rows that are deleted generate an invalid cursor position error if they are fetched. Likewise, updates to key columns operate like a delete of the old key followed by an insert on a new key and so the cursor does not see the new row.
- Mixed cursors, for example,
SQL_CURSOR_KEYSET_DRIVENandSQL_KEYSET_SIZE=n.ODBC cursors support the concept of a rowset, which is the number of rows returned on an individual call to a fetch function. For example, an application that is capable of displaying 20 rows at a time in its window might set the rowset size to 20, so that each fetch returns one window's depth of rows.
Cursor operations are also affected by the concurrency options set by the application. These are SQL_CONCUR_READONLY, SQL_CONCUR_VALUES, SQL_CONCUR_ROWVER, and SQL_CONCUR_LOCK. SQL_CONCURRENCY affects how the database engine locks rows in the result set.
The locking behavior of cursors is based on an interaction between the concurrency options and the transaction isolation level set by the application. You set the transaction isolation level with SQL_ATTR_TXN_ISOLATION, which can be set to:
- Read committed (
SQL_TXT_READ_COMMITTED) - Read uncommitted (
SQL_TXN_READ_UNCOMMITTED) - Repeatable read (
SQL_TXN_REPEATABLE_READ_COMMITED) - Serializable (
SQL_TXT_SERIALIZABLE)
In addition, an application can specify the characteristics or a cursor rather than specifying the cursor type. For example, scrollability by setting SQL_ATTR_CURSOR_SCROLLABLE or sensitivity by setting SQL_ATTR_CURSOR_SENSITIVITY. The driver then has to choose the cursor type that most efficiently provides that characteristic. Whenever an application sets any of the SQL_ATTR_CONCURRENCY, SQL_ATTR_CURSOR_SCROLLABLE, SQL_ATTR_CURSOR_SENSITIVITY, or SQL_ATTR_CURSOR_TYPE statement attributes, the ODBC driver makes any required change to the other statement attributes in this set of four, so their values remain consistent.
An application that sets statement attributes to specify both a cursor type and a cursor characteristic is running the risk of obtaining a cursor that's not the most efficient method available in that ODBC driver.
Choice of a cursor depends largely on how the database engine implements that cursor and the correct choice can have a dramatic effect on performance and locking. As a basic rule, use the cursor and concurrency level that has sufficient functionality for your application and no more. However, there are other considerations depending on your database engine such as:
- Size of result set.
- Performance of the cursor.
- Requirement for scrolling or positioning.
- Desired level of modification visibility to other applications.
Cursor library
The cursor library built into the ODBC Driver Manager attempts to imitate cursors when the ODBC driver does not have support for them. The principal settings are i) always use the cursor library (no matter what the ODBC driver supports) and ii) use the cursor library when required (if the ODBC driver does not support the required cursor). The cursor library only comes into play when an application binds columns. If the application binds columns and wants to move about the result set with SQLFetchScroll (for instance) then the ODBC Driver Manager will keep a copy of the rows retrieved in bound columns so the application can move around the result set even though the ODBC driver does not support this functionality.
Try to avoid the cursor library.
If your ODBC driver has support for the cursor you require, asking the Driver Manager to use the cursor library with SQLSetConnectAttr(SQL_USE_CURSORS, SQL_CUR_USE_ODBC) is a waste of time. When you use SQL_CUR_USE_ODBC, the cursor library will generally convert all calls to SQLFetchScroll and SQLExtendedFetch into SQLFetch calls and will often ignore SQL_ROWSET_SIZE and SQL_ATTR_ROW_ARRAY_SIZE when calling the ODBC driver. If you set SQL_ROWSET_SIZE or SQL_ATTR_ROW_ARRAY_SIZE to a value greater than 1 (to get extra performance) but then stipulate you want to use the Driver Manager cursor library, each call your application makes to SQLFetchxxx to get n rows at a time will be converted into n calls to SQLFetch.
Miscellaneous tips
- Avoid repeatedly calling
SQLDescribeParamandSQLDescribeColon the same SQL. It's much better to cache these results yourself as these metadata calls can be expensive. - If possible, leave calling
SQLDescribeParamandSQLDescribeColcalls until after callingSQLExecute, as in some ODBC drivers, this causes extra work. - Try to avoid data conversions in
SQLGetData,SQLBindCol, and so on. For example, callingSQLGetDataand asking for aSQL_C_CHARfor a column that is aCHAR.
Perl
DBD::ODBC
This section discusses the use of Perl, the Perl modules DBI and DBD::ODBC, the unixODBC Driver Manager, and the ODBC-ODBC Bridge, which provides the ODBC driver. Perl DBI and DBD::ODBC are continually being improved, so you should check you have latest versions.
The first thing we should point out is that you need to be realistic about your expectations with Perl. You are never going to get the kind of insert or select speeds from a Perl script that we have demonstrated with compiled C code in the previous sections.
DBI provides a generic interface to databases. DBD::ODBC is the DBI driver for accessing ODBC drivers. DBD::ODBC is written to work with any ODBC driver and as such it's difficult to provide specific optimisations like the ones in the previous ODBC section.
Some of the methods used by DBD::ODBC are not the most efficient use of ODBC for specific situations but are a side-effect of the generic nature of DBD::ODBC. For example, when some SQL is executed DBD::ODBC does not know if it was a SELECT statement or an INSERT statement, so a typical insert is followed by SQLNumResultCols, SQLRowCount, and SQLMoreResults calls, all of which are redundant. This is not a criticism of DBD::ODBC. It's simply a recognition of the difficulty of writing a super-efficient DBD module without knowing what the SQL is. These additional calls to SQL functions cause remote procedure calls to the ODBC-ODBC Bridge server, which slow Perl scripts down.
As an example, using the same table described in the earlier ODBC section, the following code took 15 minutes (55 inserts per second):
use DBI;
my $dbh = DBI->connect() || die "connect";
my $i;
my $sql;
for ($i = 1; $i <= 50000; $i++) {
$sql = "INSERT INTO perf VALUES (" . $i .
", 'this is a char thirty', " .
"'this is a varchar 255'," .
"{ts '2002-08-01 11:12:13.123'}, " .
$i*1.1 . ")";
$dbh->do($sql);
}
$dbh->disconnect()Unlike the C examples in the previous section, using parameterised inserts in Perl is quite a bit faster, so the above code can be written as:
use DBI;
my $dbh = DBI->connect() || die "connect";
my $sql = "INSERT INTO perf VALUES (?,?,?,?,?)";
my $stmt = $dbh->prepare($sql);
$stmt->bind_param(2, 'this is a char thirty');
$stmt->bind_param(3, 'this is a varchar 255');
$stmt->bind_param(4, '2008-08-01 11:12:13.123');
for (my $i = 1; $i <= 50000; $i++) {
$stmt->bind_param(1, $i);
$stmt->bind_param(5, $i*1.1);
$stmt->execute();
}
$dbh->disconnect();and the time for the 50000 inserts drops to 10 minutes (83 inserts a second). Using arrays of bound parameters like this:
use DBI;
my $dbh = DBI->connect()|| die "connect";
my $i;
my $sql;
$sql = "INSERT INTO perf VALUES (?,?,?,?,?)";
my $stmt = $dbh->prepare($sql);
my (@data1, @data2, @data3, @data4, @data5);
for ($i = 0; $i < 10; $i++)
{
$data1[$i] = $i;
$data2[$i] = "this is a char thirty";
$data3[$i] = "this is a varchar 255";
$data4[$i] = "2002-08-01 11:12:13.123";
$data5[$i] = $i * 1.1;
}
$stmt->bind_param_array(1, \@data1);
$stmt->bind_param_array(2, \@data2);
$stmt->bind_param_array(3, \@data3);
$stmt->bind_param_array(4, \@data4);
$stmt->bind_param_array(5, \@data5);
$data2 = "this is a char thirty";
$data3 = "this is a varchar 255";
$data4 = "2002-08-01 11:12:13.123";
my %status;
for ($i = 1; $i <= 5000; $i++) {
$data5 = $i * 1.1;
$stmt->execute_array(\%status);
}
$dbh->disconnect();
does not seem to make any real difference. This is probably because at this time, array bound parameters are actually executed in ODBC terms with SQL_PARAMSET_SIZE = 1, so it is unsurprising that there is no speed increase when compared with the previous example.
Using the same table of 50000 rows and writing simple Perl to fetch the data, we might use:
#!/usr/bin/perl
use DBI;
my $dbh = DBI->connect()|| die "connect";
my $sql;
$sql = "SELECT * FROM perf";
$stmt = $dbh->prepare($sql);
$stmt->execute();
my @row;
while(@row = $stmt->fetchrow_array()){};
$dbh->disconnect();This takes around 93 seconds (537 rows a second).
Using bound columns, we would write:
use DBI;
my $dbh = DBI->connect()|| die "connect";
my $sql;
$sql = "SELECT * FROM perf";
$stmt = $dbh->prepare($sql);
my $nf = $sth->{NUM_OF_FIELDS};
my @cols;
for (my $i = 1; $i <= $nf; $i++) {
$sth->bind_col($i, \$cols[$i]);
}
$stmt->execute();
my @row;
while($stmt->fetch()){};
$dbh->disconnect();but this appears to take a similar amount of time. This is no surprise, for the same reasons given in the earlier ODBC section.
So, the conclusion here is that if you want the best insert or fetch speed use C, but if you want the flexibility and portability of Perl, you need to accept it's going to be slower.
DBD::Proxy
For anyone wanting a Perl-only solution, DBD::Proxy offers similar functionality to that of the ODBC-ODBC Bridge. DBD::Proxy transfers DBI calls and data between the client and server. Since it is only doing the DBI calls, and the ODBC-ODBC Bridge is doing all the ODBC calls beneath DBI, you would expect the ODBC-ODBC Bridge to be slower than DBD::Proxy, however this is not usually the case.
Using the same tables listed in the ODBC section in this document, the results below are for 50000 inserts and a select on all columns for the 5000 rows to an ISAM database using the Easysoft ODBC driver. All values are in seconds and the average of 3 runs.
CPUu and CPUs are user and system CPU times.
| test | Easysoft ODBC-ODBC Bridge | DBD::Proxy | ||||
|---|---|---|---|---|---|---|
| CPUu | CPUs | Elapsed | CPUu | CPUs | Elapsed | |
| insert | 19.73 | 22.72 | 84.18 | 58.17 | 5.31 | 151.54 |
| select | 7.01 | 7.09 | 31.94 | 2.52 | 0.61 | 48.33 |
When these numbers are used to calculate the inserts per second and rows retrieved per second:
| test | Easysoft ODBC-ODBC Bridge | DBD::Proxy |
|---|---|---|
| inserts per second | 594 | 330 |
| rows retrieved per second | 1565 | 1035 |
As we have shown earlier, turning autocommit off and committing all 50000 inserts at the end speeds up the inserts per second with most databases, but this works equally for both Easysoft ODBC-ODBC Bridge and DBD::Proxy.
DBD::Proxy does have some optimisation settings like proxy_no_finish, proxy_quote, and RowCacheSize. The ODBC-ODBC Bridge has block fetch mode, but this does not apply to ODBC 2.0 applications (which DBD::ODBC is before version 0.45_2) and after 0.45_2 DBD::ODBC binds the columns itself anyway.
With the following settings the select test was run again:
proxy_quote = "local" proxy_no_finish = 1 RowCacheSize = 100
| test | Easysoft ODBC-ODBC Bridge | DBD::Proxy | ||||
|---|---|---|---|---|---|---|
| CPUu | CPUs | Elapsed | CPUu | CPUs | Elapsed | |
| select | 7.31 | 7.17 | 32.19 | 3.6 | 0.14 | 16.12 |
which puts the final rows retrieved per second at:
| test | Easysoft ODBC-ODBC Bridge | DBD::Proxy |
|---|---|---|
| rows retrieved per second | 1553 | 3102 |
So, in their default and best configurations we could find, the ODBC-ODBC Bridge was quicker than DBD::Proxy when inserting. The ODBC-ODBC Bridge is also quicker than DBD::Proxy under its default configuration when retrieving rows. However, if memory constraints permit you to use RowCacheSize with higher values, DBD::Proxy is quicker than ODBC-ODBC Bridge at row retrieval.
We started by saying ODBC-ODBC Bridge RPCs every ODBC call but DBD::Proxy acts at a higher level and only has to RPC DBI calls. One area DBD::Proxy might possibly do a lot better is over encrypted connections. Our experience is that encryption of these sorts of data streams can be time consuming. The more network calls made, the worse the effect of encryption becomes. There are so many different encrpytion tunnels, (for example, SSH, zebedee, and so on) we have not verified this.
PHP
Most of the comments made under the Perl section apply equally to PHP. PHP is however different from Perl DBI DBD::ODBC in that it provides a PHP interface to ODBC. ODBC functions are wrapped in C code written for PHP. However, a lot of the flexibility of ODBC is hidden from the PHP user and this reduces the opportunity for tuning PHP code for the fastest ODBC access. PHP always uses bound columns when retrieving a result set and all our experiments showed very little difference in speed between different insertion and retrieval methods.
Having said that, PHP is quite fast. The standard table we have used throughout this document of 50000 rows containing 5 mixed type columns is retrieved in 90 seconds (555 rows a second).
If you're using PHP with Microsoft SQL Server, there are two important points you should note:
-
PHP attempts to set the cursor type in any ODBC driver that successfully returns
SQL_FD_FETCH_ABSOLUTEin theSQLGetInfocall forSQL_FETCH_DIRECTION. The cursor that's requested depends on the version of PHP. Older versions (around 4.0.x and 4.1.x) set the cursor toSQL_CURSOR_DYNAMICbut later versions (4.2.x) seem to set the cursor toSQL_CURSOR_FORWARD_ONLY.We believe the original reason for setting the cursor to
SQL_CURSOR_DYNAMICwas because, for Microsoft SQL Server, this is a server-side cursor that allows Multiple Active Statements. Server side cursors in Microsoft SQL Server are more expensive.SQL_CURSOR_FORWARD_ONLYis the default cursor and this is not a server-side cursor and does not allow Multiple Active Statements .The other drawback of Microsoft SQL Server server-side cursors is that they do not support all SQL statements. Server cursors do not support any SQL statements that generate multiple result sets, therefore they cannot be used to execute a stored procedure or a batch containing more than one
SELECT. - Please refer to the notes in the Enabling ODBC support in PHP under Apache about PHP and PHP code hanging when using multiple active statements.
Microsoft Access
There appear to be four main methods of ODBC access from Microsoft Access:
-
ADO
ActiveX Data Objects support different cursor types, are a wrapper over OLE DB, and are often used under IIS.
A typical ODBC access pattern for ADO is:
SQLSetConnectAttr(SQL_MAX_ROWS=0) SQLSetStmtAttr(PARAM_BIND_TYPE = 0) SQLSetStmtAttr(PARAM_BIND_OFFSET_PTR = 0) SQLSetDescField(OCTET_LENGTH_PTR = 0) SQLParamOptions(1,0) SQLExecDirect(SELECT * FROM table) SQLRowCount SQLNumResultCols Loop through columns { SQLDescribeCol(col) SQLColAttribute(to get SQL_COLUMN_UNSIGNED, SQL_COLUMN_UPDATABLE and SQL_COLUMN_LABEL) } SQLSetStmtAttr(ROW_BIND_TYPE=n where n>0) SQLSetStmtAttr(ROW_BIND_OFFSET_PTR=ptr where ptr != 0) SQLSetStmtAttr(RETRIEVE_DATA=0) Loop through columns: { SQLBindCol } SQLSetStmtAttr(ROWSET_SIZE=1) Loop though rows: { SQLExtendedFetch }Unfortunately, this is one of the slowest ways of getting column data with the ODBC-ODBC Bridge. The ODBC-ODBC Bridge deliberately does not support row-wise binding ODBC calls; instead, it binds the columns using column-wise binding (to avoid structure alignment problems between different machines). An entire row is retrieved in one call to
SQLExtendedFetch(which is good) but then ODBC-ODBC Bridge needs to translate that from column-wise binding to row-wise binding for the application. This method also uses more memory because the ODBC-ODBC Bridge client needs to allocate memory for one row of column-bound columns.Setting
BlockFetchSizein the ODBC-ODBC Bridge is irrelevant here as the application does its own binding. -
Dynasets
Dynasets can be used where there are one or more unique columns (if there aren't any unique columns, JET drops back to Snapshot mode).
What JET does depends on whether the DB engine can support Multiple Active Statements. If it can, recent Jets (JET 4+) appear to make the following ODBC calls:
SQLSpecialColumns SQLGetTypeInfo(various) SLColumns SQLStatistics (to locate unique columns) stmt1 = SQLExecDirect(select uniqcol1,uniqcoln from table) stmt2 = SQLPrepare(select col1,col2,coln from table where uniqcol1=? and uniqcoln=?) From here on it enters a loop reading one row from stmt1 to use as parameters in stmt2: Loop { SQLFetch(stmt1) SQLGetData(stmt1, uniqcol1) . . SQLGetData(stmt1, uniqcoln) SQLBindParameter(stmt2, p1) . . SQLBindParameter(stmt2, pn) SQLExecute(stmt2) SQLFetch(stmt2) SQLGetData(stmt2, col1) . . SQLGetData(stmt2, coln) SQLFreeStmt(SQL_CLOSE) }This method means that on
stmt1the one call toSQLExecDirectreturns a result set containing the unique columns for every row in the table. and onstmt2, eachSQLExecutereturns a result set containing only one row (the row that contains the current values foruniqcol1..n).The ODBC-ODBC Bridge has a block fetch mode that may be used to speed up this ODBC access pattern. In this scenario, setting the ODBC-ODBC Bridge's connection attribute,
BlockFetchSizeto1is the quickest. In this mode, the ODBC-ODBC Bridge binds the columns in the result sets and asks for one row at a time; the row data is cached by the ODBC-ODBC Bridge whenSQLFetchis called and returned to Jet when it callsSQLGetDatafor each column.With
BlockFetchSizeset to1, the time taken to retrieve an entire table is often as little as half of that as whenBlockFetchSizeis set to0, although this depends on the number of columns and unique columns in your table. -
ODBC direct
ODBC direct uses a forward-only cursor and the SQL is passed through to the DB engine.
A typical ODBC access pattern looks like this:
SQLGetTypeInfo(for all types) SQLSetStmtAttr(SQL_ROWSET_SIZE, 100) SQLExecDirect(SELECT * FROM table) SQLNumResultCols Loop through columns { SQLColAttributes(coln) SQLBindCol(coln) } Loop until no more data { SQLExtendedFetch(SQL_FETCH_NEXT, 1) }This is a particularly fast way of reading a result set as it:
- Reads from the start to the end of the result (forward only).
- Sets the
ROWSET_SIZEto 100 and retrieves 100 rows at a time.
For the ODBC-ODBC Bridge, this is one of the fastest ways of retrieving a result set (as was demonstrated in Using ODBC directly). This is always faster than Jet's dynaset mode.
-
Snapshot
Snapshot produces a read-only result set where you can use first, next, last, and so on, and is the fallback for dynaset if the table does not contain unique columns.
A typical ODBC access pattern looks like this:
SQLSpecialColumns SQLGetTypeInfo(various) SQLColumns SQLGetTypeInfo(various) SQLExecDirect(select col1, col2, coln from table) Loop through rows: { SQLFetch SQLGetData(col1) . . SQLGetData(coln) }This access pattern is greatly speeded up by using the ODBC-ODBC Bridge's block fetch mode. Setting
BlockFetchSizeto100reduces the time taken to retrieve the table massively and since the result set is read-only, this is safe to do.
Miscellaneous applications
For applications where you don't have access to the source code or cannot build it yourself, there is still one possible optimisation. The ODBC-ODBC Bridge contains a block fetch mode that can be used to retrieve multiple rows of data at once and then hand them off to the application one column at a time.
Many applications make ODBC calls like this:
SQLExecDirect(SELECT * FROM table)
while(SQLFetch() succeeds)
{
SQLGetData(column1)
.
.
SQLGetData(columnn)
}There is nothing wrong with the code, but it is certainly not the quickest method to retrieve result sets by using the ODBC-ODBC Bridge. As discussed in Using ODBC directly, binding columns to the result set and asking for multiple rows per fetch is a lot faster. If your application uses the above method but you are not able to change it then you may be able to use the ODBC-ODBC Bridge's block fetch mode. The ODBC-ODBC Bridge's block fetch mode comes in to play if you set the BlockFetchSize connection attribute and call a fetch API when certain other conditions do not apply. The following conditions must be true if the ODBC-ODBC Bridge is to enter block fetch mode:
- Cursor type must be
FORWARD_ONLY(the usual default). RowArraySizemust be1.- There mustn't be any bound columns.
- if the ODBC driver is Microsoft SQL Server then the application must be ODBC 3.x.
The Microsoft SQL Server driver will not return
RowsProcessedPtrto an ODBC 2.0 application. - The row bind offset must be
0g(the ODBC default). - You must not be using
SQLExtendedFetch
If BlockFetchSize is set in the ODBC-ODBC Bridge client DSN, and the above conditions apply, the ODBC-ODBC Bridge client allocates space for column or row data and binds the columns. SQLFetch is called and now the ODBC-ODBC Bridge client has n rows of data. As the application calls SQLFetch, the ODBC-ODBC Bridge client moves through the bound result set one row at a time. When the application calls SQLGetData, there is not a round trip to the server. The column data is supplied from memory. The only difference here is that the ODBC-ODBC Bridge client does not know what data type the application will ask for the columns as, so all columns are bound as SQL_C_DEFAULT. When the application calls SQLGetData and specifies the data type required, the ODBC-ODBC Bridge client does the conversion. The application should behave as it always has but result sets will be retrieved more quickly.
Do not use block fetch mode if your application does positioned updates or deletes. BlockFetchSize = 1 should be safe for any application and is often still faster than not enabling block fetch mode.
To turn on block fetch mode, add the attribute BlockFetchSize=n to your ODBC connection string or DSN. A value of 0 means block fetch mode is turned off (the default). A value for n (where n>0) is the number of rows to fetch in one go. BlockFetchSize may be set up to 100 but there is a balance between memory use and speed. As BlockFetchSize is increased, more memory at the client end is required.
Databases
Microsoft SQL Server
There are a number of entries in the ODBC-ODBC Bridge knowledge base relevant to connecting to Microsoft SQL Server.
Positioning of the ODBC-ODBC Bridge server
With the ODBC-ODBC Bridge, there are two possible configuration scenarios:
- The ODBC-ODBC Bridge server is installed on the same machine as Microsoft SQL Server.
- The ODBC-ODBC Bridge server is installed on a different machine to Microsoft SQL Server.
Normally it is OK to do 1) but in some situations responsiveness of the ODBC-ODBC Bridge server is poor when installed on the same machine as Microsoft SQL Server.
Microsoft introduced changes to Microsoft SQL Server 7.0 that may cause connections to an ODBC-ODBC Bridge server and subsequent operations to be very slow. These settings elevate the priority of SQL Server to such an extent that other processes on the machine do not get a look in. (For example, when someone executes a query, Task Manager even stops displaying.) If you are running Microsoft SQL Server, and the ODBC-ODBC Bridge server is running on the same machine as SQL Server, you should try the following:
- Turn off the following settings, which are available from the Properties menu of the Enterprise Manager. The settings are Boost SQL Server Priority on Windows NT and Use NT fibres. When these are set, Windows is so busy servicing SQL Server, the
accept()in the ODBC-ODBC Bridge server can take some time due to Windows not scheduling any other processes. - Move the ODBC-ODBC Bridge server onto another Windows machine.
In general, we would recommend running the ODBC-ODBC Bridge server on a different machine to SQL Server for best responsiveness.
Further evidence for this comes from a typical scenario we tried running an in-house ODBC benchmark through to:
- An ODBC-ODBC Bridge server on the same machine as Microsoft SQL Server.
- An ODBC-ODBC Bridge server on a different machine to Microsoft SQL Server.
The tests cover the creation of tables containing different column types, insertion by using SQLExecDirect, parameterised inserts, and the selection of rows by using various methods including parameterised selects.
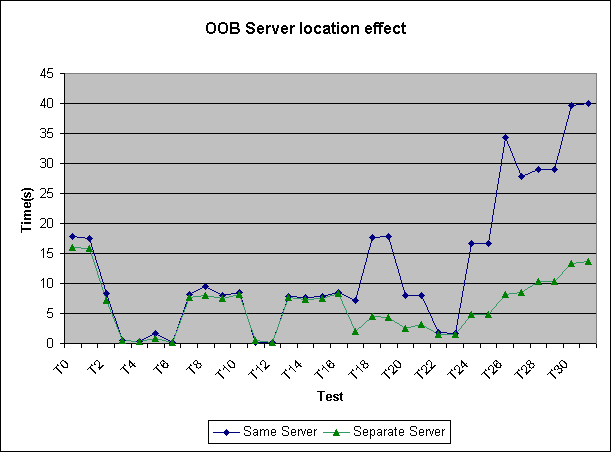
Here we used Microsoft SQL Server Enterprise Edition v8.00.760(SP3) on a 2 CPU machine with 1 GB RAM. SQL Server was configured to use only 1 CPU. We turned off Boost SQL Server Priority on Windows NT and Use NT fibres. The SQL Server machine was doing nothing else. In the case where the ODBC-ODBC Bridge server was on a different machine, it was running NT 4.00.1381 and was on the same LAN as the Microsoft SQL Server machine. Clearly, in this case it is a lot faster to run the ODBC-ODBC Bridge server on a separate machine to Microsoft SQL Server.
Also, it is worth avoiding putting the ODBC-ODBC Bridge server on your Primary Domain Controller (PDC) or Secondary Domain Controller (SDC) if you have OS authentication turned on, as experiments at Easysoft have shown this to be faster.
Miscellaneous
Here are a few tips for speeding up access to Microsoft SQL Server through the ODBC-ODBC Bridge:
- If you are inserting a lot of data and don't need to know how many rows were inserted. prefix your SQL with
SET NOCOUNT ON. This tells Microsoft SQL Server you do not need to know the number of rows affected and so you are not going to need a useful result fromSQLRowCount. -
SQLPrepareandSQLExecuteare often more expensive thanSQLExecDirect. The main reason for this is that SQL Server does not directly supportSQLPrepareandSQLExecute. The Microsoft SQL Server ODBC driver providesSQLPrepareandSQLExecutesupport by creating a temporary procedure; this is one extra round trip to the database overSQLExecDirect. There is also an impact on yourtempdbas this is where temporary procedures are created (refer to theSQLSetStmtAttrattributesSQL_USE_PROCEDURES_FOR_PREPARE).If you're writing an application that issues specific SQL statements and intend distributing that to multiple users in your organisation, a procedure would be more appropriate. Having many users issuing the same SQL in
SQLPrepareandSQLExecuteis going to start filling yourtempdbup with multiple occurrences of same temporary procedure.